You Know You Can Be Too Fit
A review on the concept of overfitting

No, this isn't an incitement on the culture of cross-fit or other fitness related clubs. I've never had much of an issue as long as people are getting in shape and enjoying themselves that's fine. I know people find they talk about their new found hobby too much but so does anyone with a new found hobby. Have you ever talked to someone who just started improv classes?
Anyway, the overfitting issue that I'm referring to has more to do with data and the idea that less is more. We all live with the idea that the more information we have, the better we are equipped at dealing with an issue, but that simply is not the case. Overfitting is when a model performs extremely well on the data it has been trained on, but poorly on data it has never seen. Imagine you are cooking at a friends house. You have trained in your kitchen and have become so used to the set up there that when you more to a kitchen you aren't used to, you become disoriented. You may know basic things like where the utensils are, but because you are so fit on how your kitchen is set up, you predict poorly on things are in your friends kitchen (also, their kitchen is a lot nicer then yours and you feel self conscious.) It's not a perfect metaphor, but it gives the sense of the issue.
To demonstrate the issue and what can be done about it, I'm going to use the Ames Housing Data from Kaggle. In this dataset, I was given information on houses and the price they sold at For the first model I ran, I wanted to show an example of someone trying to be restrained and pick features based on their own thoughts and criteria. The following columns were picked and run through the model.

The linear regression returned the following R-squared results. The closer the score gets to 1.00, the better the model is performing. The first score is how the model performs on the training data, while the second score shows how the model performs of data it has never seen (test data). The following are the top 10 most important features for the model.

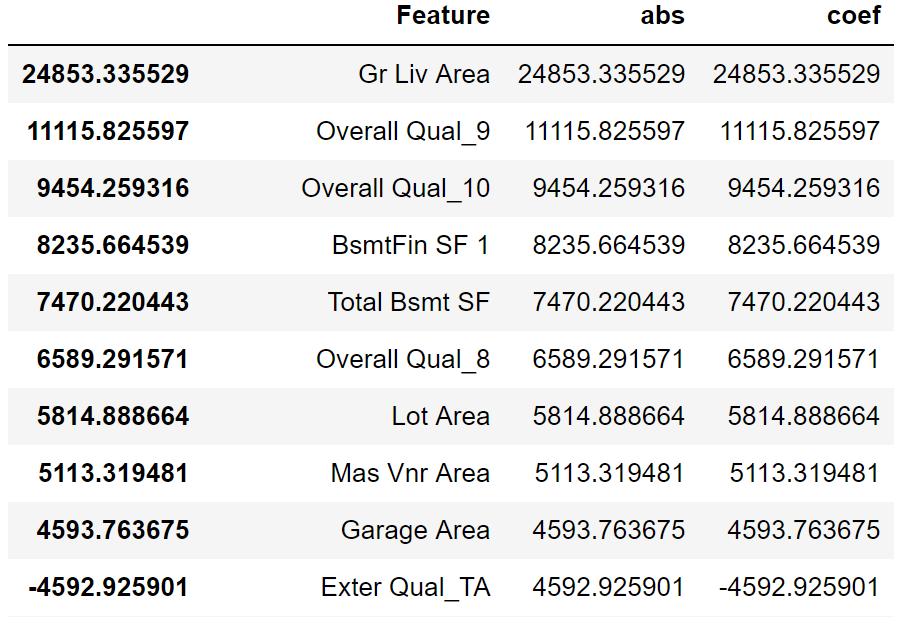
The model is not performing to badly, but we can see a drop off of about 15 points from the training to the test. This gap is what we are trying to diminish with minimizing overfitting. Even though I has very careful to select only a few items, the model is still showing signs of overfitting.
So how much better can the computer do at. There are a few tools at our disposal for what is called regularization, but today I'm going to focus on LASSO. The way regularization works in general is that it places a penalty on features that are correlated to each other or are not relevant to the model at all. LASSO places such a big penalty that it effectually removes features all together.
For the LASSO regression, I gave the model access to all the 80 columns of features available to it. After some features are dummied, this number will increase dramatically.

We can see that both of the scores have gone up. This is to be expected with the training data as it will always increase with new data. However, the fact that the test data increased and the gap has shrunk shows that LASSO is at least one tool that can be used. Further tuning with hyperparameters can be done to get a greater effect.
For a further look at the code and other analysis done, Please visit my Github Portfolio here.


Comments
Post a Comment